The cheapest line item in my AI app is the AI
When you ship a consumer app that leans on a large language model, the standard cost warning is always the same: watch your inference bill. Cap your usage. The model will eat your margin.
After running mine live for a while, I can report the opposite. The AI is the cheapest, most predictable line item I have — and the economics that actually matter turned out to be somewhere else entirely.
What the model actually costs
The app uses a small, cheap model for its AI features, and I built it to call that model as little as possible:
A small model, not a frontier one, for tasks that don’t need a frontier one.
Hard caps on output length and low temperature — predictable tokens in, predictable tokens out.
Aggressive caching: a cache hit rate north of 80%, so most requests never reach the model at all.
A free, deterministic data source tried first; the model is only the fallback.
A per-user rate limit, so no single user can run up the bill.
Add it up and the cost to serve an active user lands on the order of a tenth of a percent of what they pay for a monthly subscription. On the P&L, the model is a rounding error.
The lesson isn’t “models are cheap now,” though they are. It’s that AI cost is an architecture decision, not a procurement one. You don’t get cheap inference by negotiating price-per-token; you get it by calling the model less — cache, cap, prefer deterministic sources, batch. The team that designs for fewer, smaller calls beats the team with a better rate card. That bullet list above is really a pricing decision disguised as architecture.
The line item that actually moves the margin
The expensive part of the app has nothing to do with AI. It’s distribution.
Put it on a single $10 transaction. Route it through iOS in-app purchase and the platform fee takes $1.50 to $3.00 of it; the inference behind that customer’s usage costs a fraction of a cent. The channel takes a couple hundred times what the model does, on the same dollar. So the app applies the long-established “reader” principle — apps from Netflix to Spotify to Kindle handle commerce on the web and use the iOS app for access. That’s the architecture I ended up with. (The formal App Store carve-out is narrow, and the rules are in flux post-Epic and under the EU’s DMA — so the point is the principle, not any one loophole.)
A pricing person’s way to say it: your distribution channel’s take rate is usually a far bigger lever on margin than your cost of goods. I spend my day setting price inside a hardware P&L at scale, where a point of margin is real money and the structure — where value gets captured, not what it costs to make — dominates the model. The app just let me run the same logic at the opposite extreme: near-zero unit cost, and the structure still decides everything.
Two pricing reflexes that break when cost rounds to zero
When your unit cost rounds to zero, two reflexes that served older businesses well both break.
Cost-plus pricing makes you look cheap to your own product. Price a near-zero-cost feature on cost and you’ll price it near nothing — which tells the buyer it’s worth near nothing.
Per-usage metering makes the user anxious about a meter that’s measuring almost nothing — you collect all of the anxiety and almost none of the revenue.
Metering isn’t always wrong, though. It’s the right model when each call does expensive, legible work — a coding agent like Cursor or Claude Code, a per-resolution support agent — because there the meter tracks something the customer can see is worth paying for. It fails only when both the per-call cost and the per-call value are low, which is exactly the consumer-app case: each call is cheap and invisible, so the meter just generates worry. There, bundle pricing and value-anchored tiers win.
The same logic set my lifetime tier. I didn’t price it from cost; I priced it for what someone would pay for the certainty of never being asked to pay again — a willingness-to-pay number, not a cost number. A lifetime plan is normally a recurring-revenue anti-pattern: you trade a stream for a lump and a permanent obligation to serve. I took it deliberately, precisely because near-zero marginal cost makes that obligation nearly free to honor.
Then, at launch, I gave Pro away to the first cohort of families. That’s revenue I’m choosing not to collect — and it’s a standard early-stage sequencing move, not generosity. At this stage the binding constraint isn’t monetization; it’s getting enough engaged users in the door to learn what makes them stay. The risk you take on is anchoring — teach people the thing is free and some never convert — which is why it’s the first cohort, not forever.
Where the economics actually live
Once inference rounds to zero and you’ve protected your take rate, unit economics stop being about cost to serve at all. They’re dominated by activation and retention. If people sign up and ghost, no pricing tier saves you. If they stick, the model cost is noise. In a world of cheap inference, the highest-leverage “pricing” work often isn’t pricing — it’s getting someone to the “oh, I get it” moment fast enough that they come back.
The transferable part
If you price or build AI products, retire one reflex: treating token cost as the central economic question. It was the right worry in 2023; it’s increasingly the wrong one for products shaped like mine. The honest caveat is the frontier: multi-step agents and reasoning loops have pushed per-task cost up even as per-token prices fall, and cost still matters enormously there. But for the broad middle of consumer and SaaS AI features, cost-to-serve is trending toward noise.
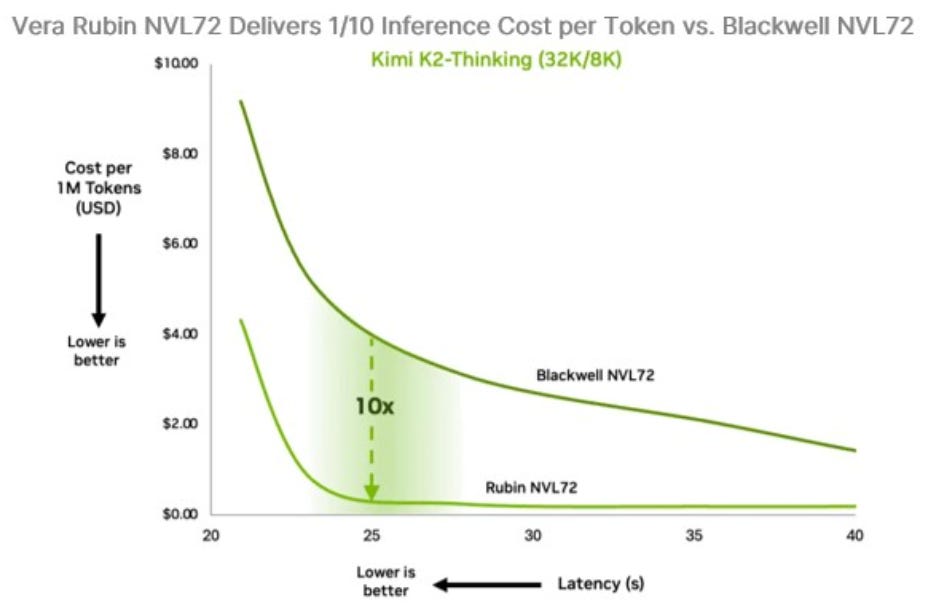
Watch where the supply side is pushing it. NVIDIA’s published comparison for its next-generation Vera Rubin platform puts inference cost per token at roughly a tenth of the current Blackwell generation’s at the same latency — on one reasoning workload, with the usual caveat that the number moves with model and operating point. The cost floor under inference keeps dropping. But the direction was never the interesting part. The interesting question is who keeps the margin when a token costs almost nothing — and it isn’t the resellers metering tokens, or the SaaS priced on cost. It accrues to whoever prices the system and the relationship. That’s the same lesson the app taught me, three orders of magnitude down.
The questions that decide whether an AI product makes money are the old, unglamorous ones: what take rate your channel imposes, how you package against willingness to pay, and whether you keep the user long enough for any of it to matter.
Price the value and the relationship — not the inference. The inference was never going to be the expensive part.